在自然語言推理的任務中,語言模型通常會傾向於使用句子中表層資訊或特徵來做預測,但是這會造成模型在面對與訓練資料有不同分佈的資料時無法做出正確的判斷。近年來有一些模型或演算法可以在與訓練資料分佈不一的資料集上取得好的表現,然而這些方法在原本的資料分佈下的成績就會變差做為妥協。
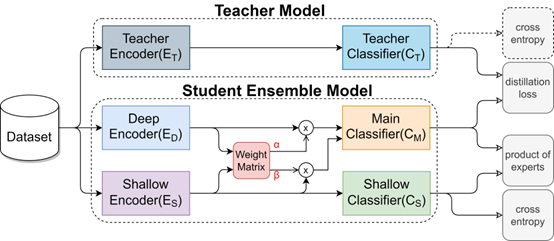
因此,我們發表一個新的模型結合了深層和淺層的語言資訊來讓模型能夠更有效的掌握句子的語意,然後使用知識蒸餾的技術來更進一步讓模型能有更好的能力學習在更多的資料上。我們使用各式各樣的自然語言推理的資料集來測試我們的模型,並且證明我們的模型在各種不同資料分佈的資料集中皆能表現優異並且效能上超越之前最先進的模型。